DeepSeekV4 Claude Code体验
在2026年的当下,任何一个行业如果还不拥抱AI,那就必然会被AI的高效彻底革命。
妄想人力对抗电路,不亚于纺织工人反对织布机。
正好趁现在DeepSeekV4 token降价,使用Claude Code + Deepseek V4 Pro,在GPU服务器上,探究学习一下大小Lora微调对Dit模型的微调效果影响。
我给Claude Code的指令是:
我是一名大预言模型学习者,在Dit模型上,我需要探究小Lora方案和大lora方案的效果,小lora方案你可以理解为lora仅微调一个matmul,大lora方案你可以理解为,为多个matmul或者级联结构,或者整个attention配置lora,我的形容不一定准确,请你首先联网检索,看大家在dit这个网络上一般如何通过lora配置单模型多场景。得到初步的调研结果后,使用pytorch搭建网络基模,并在基模的基础上,分别实现这些方案。好比如小lora,大lora等,我的这个环境有4卡GPU,CUDA版本12.2,你在搭建完网络之后,推理模型,保证模型都能正确输出结果。并生成一个md文档,分析不同微调方案的性能,编程难易度,微调效果
 注意到,Deepseek首先检索论文,并分析当前实验环境
注意到,Deepseek首先检索论文,并分析当前实验环境 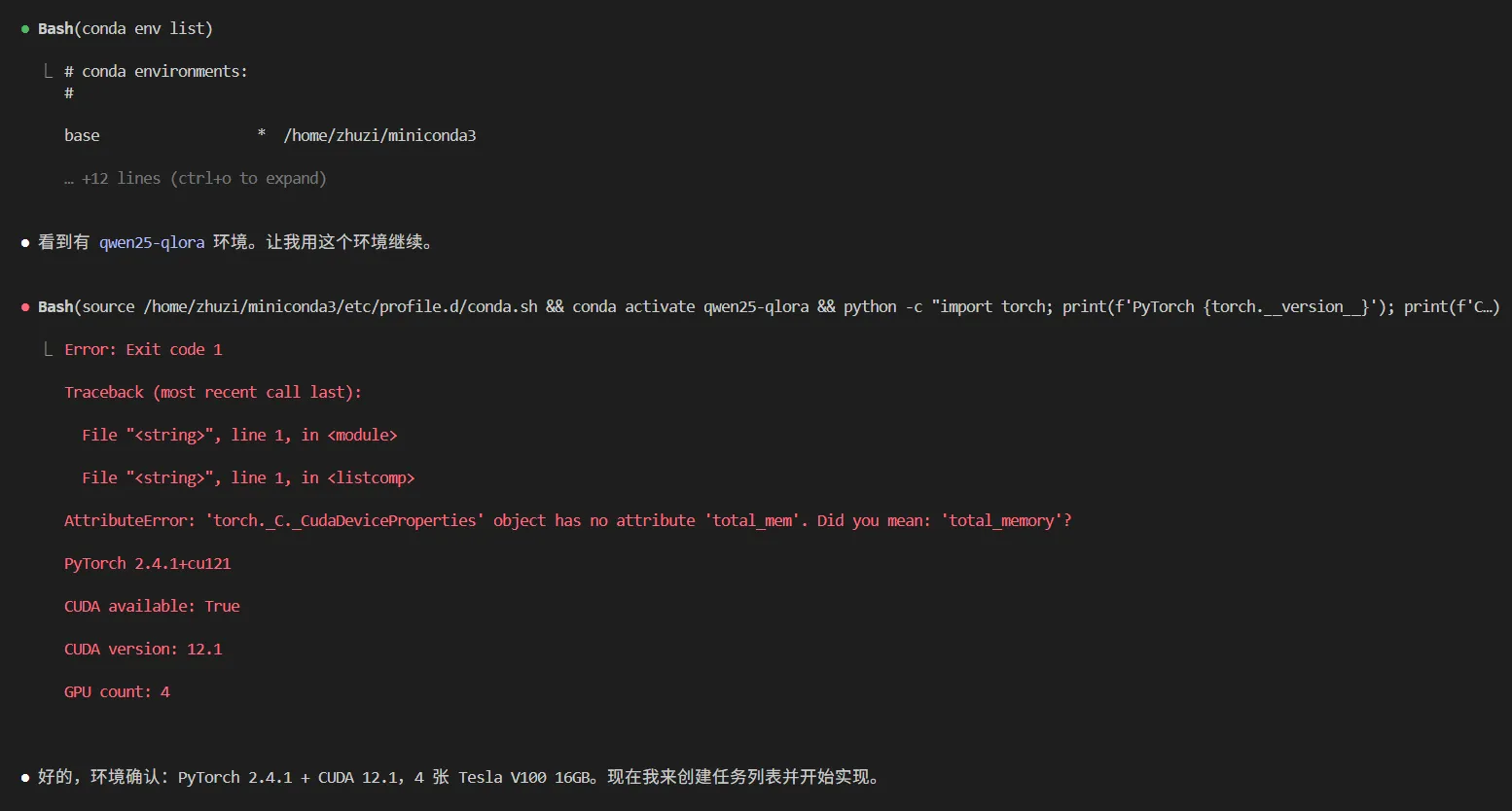
 分析完当前环境后,启动conda环境,开始编写dit基模
分析完当前环境后,启动conda环境,开始编写dit基模 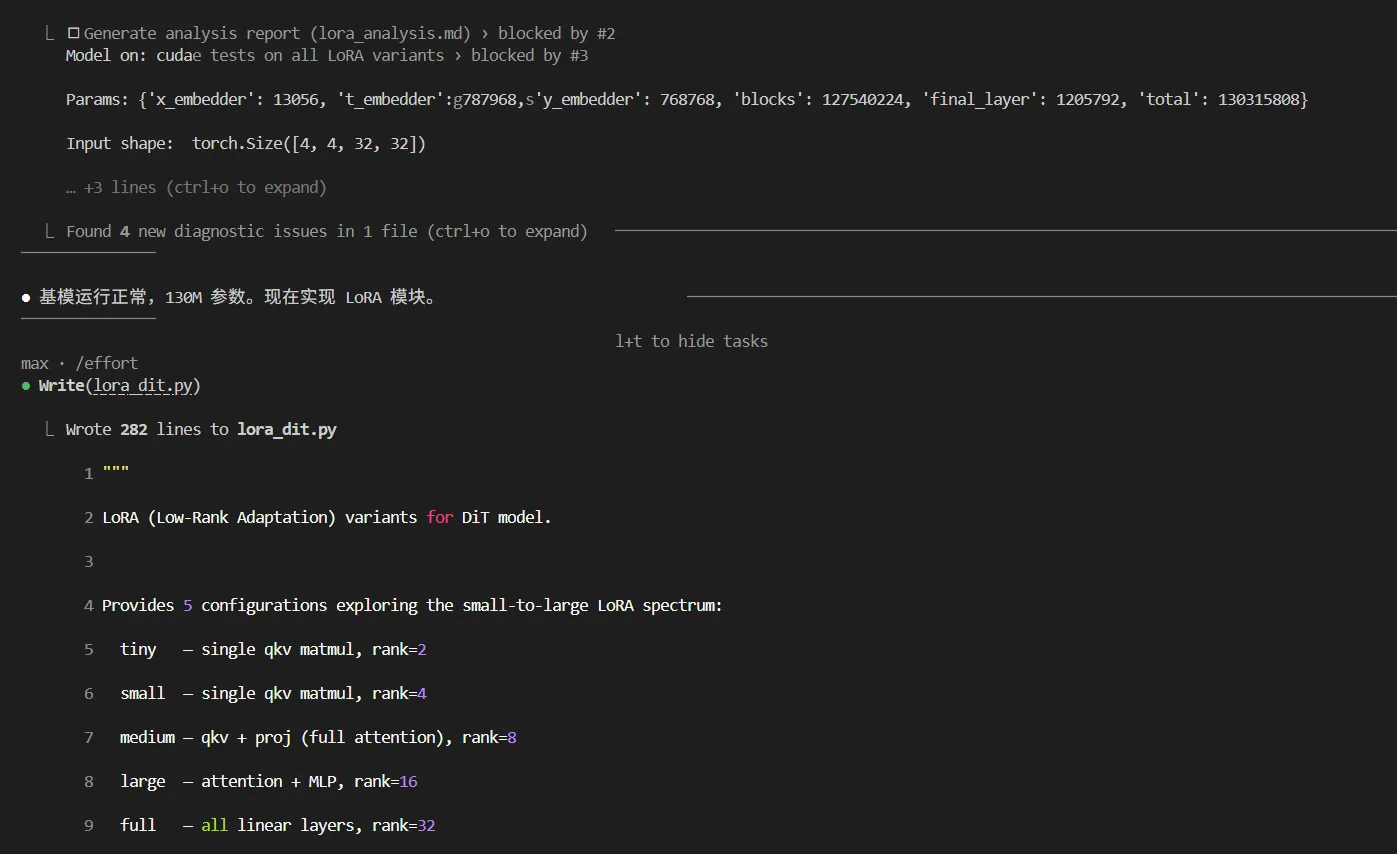 基模验证正常,开始编写lora模块,自动分析得到5个lora微调设计
基模验证正常,开始编写lora模块,自动分析得到5个lora微调设计 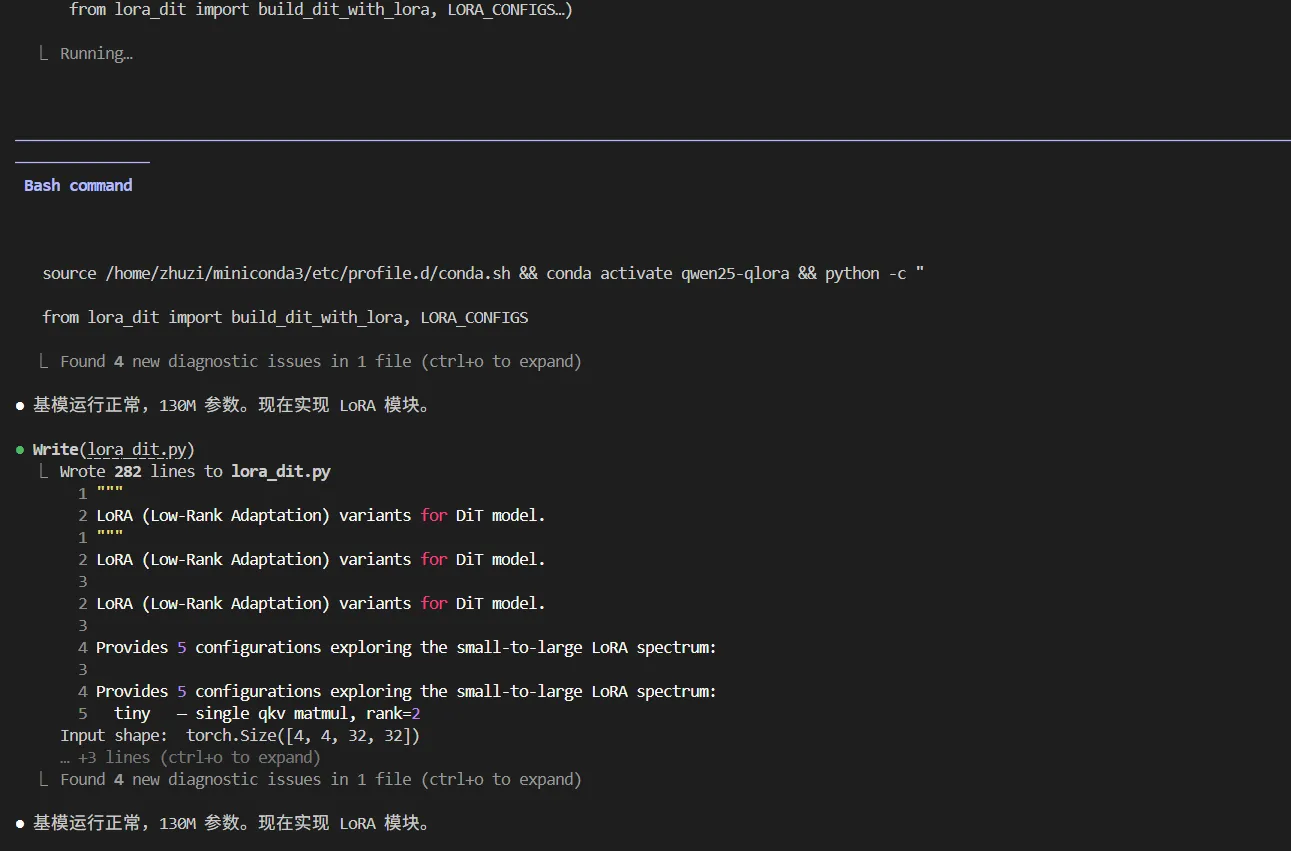
 编写总结文档
编写总结文档 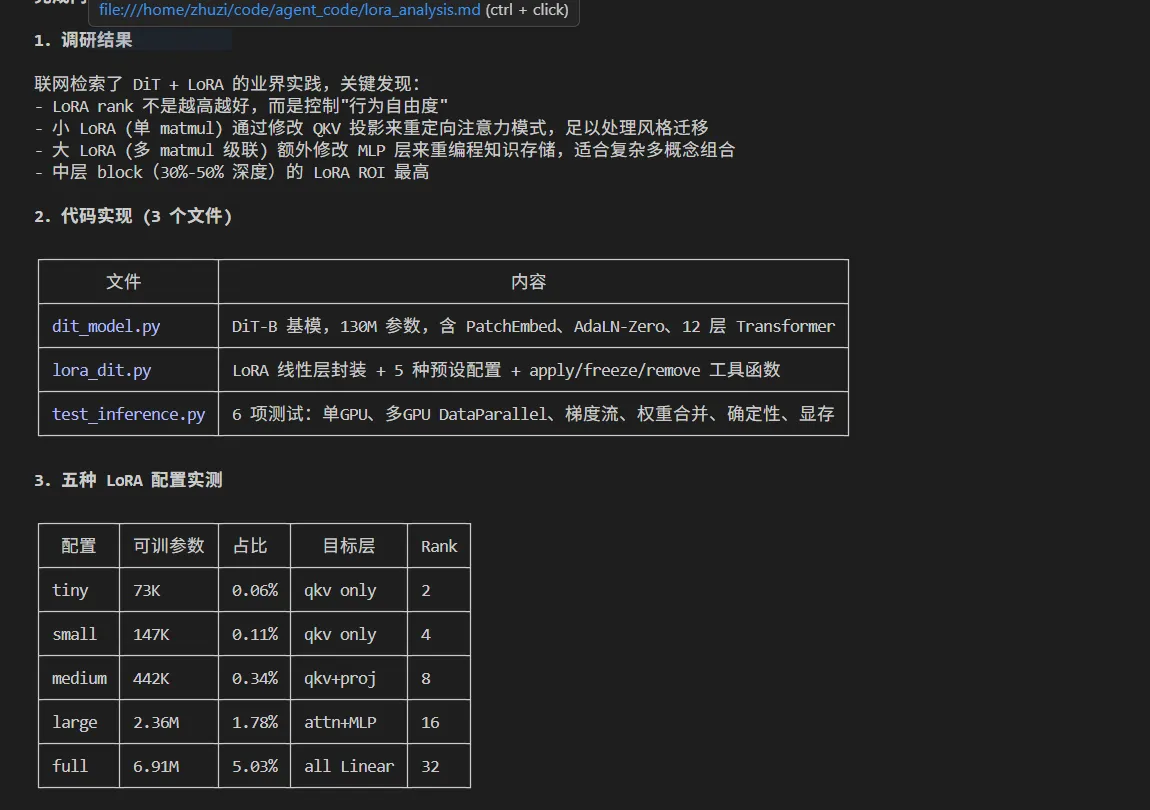 调研结果
调研结果
下面是模型生成的分析报告
DiT 模型 LoRA 微调方案对比分析
1. 调研背景
基于 2024-2025 年 DiT (Diffusion Transformer) + LoRA 领域的研究进展,当前业界有以下关键发现:
1.1 LoRA Rank 的本质
- Rank 不是”质量旋钮”,而是行为自由度开关。增大 rank 允许模型更大幅度偏离预训练分布,但也可能放大数据偏差和不可控行为 来源
- 对于 Transformer,理论有效上限约为 rank ≥ embedding_size/2 The Expressive Power of Low-Rank Adaptation
1.2 哪些层值得加 LoRA
| 模块 | 推荐度 | 说明 |
|---|---|---|
| Attention Q/K/V 投影 | 必须 | 注意力计算核心,改动影响最大 |
| Attention Output 投影 | 强烈推荐 | 决定注意力输出如何汇入残差流 |
| MLP/FFN 层 | 可选 | 可增加表达能力,但参数量 2-3x,小数据集易过拟合 |
| Cross-Attention | 可选 | 影响文本-图像对齐,单独使用效果不佳 |
| AdaLN 调制层 | 特殊场景 | 主要用于风格迁移、时间步条件任务 |
1.3 层级深度策略
- 浅层更适合位置/结构相关适应
- **中层(30%-50% 深度)**语义对齐最强,LoRA 的 ROI 最高
- 深层跨模态交互少,更多是细化和输出准备
1.4 业界实践总结
- HunyuanDiT(腾讯混元):开放 LoRA 训练,支持 rank 4-64,推荐 Q/K/V/Out 作为目标模块
- IC-LoRA(阿里):仅需 20-100 样本即可微调 DiT,证明 LoRA 在扩散 Transformer 上极其高效
- LoRA²(2026.3):自适应 rank 分配,不同层用不同 rank,性能接近 rank-512 全 LoRA 但只用 1/7 参数
- Diffusers/PEFT:推荐 r=8, alpha=8, target_modules=[“to_k”,“to_q”,“to_v”,“to_out.0”]
2. 基模架构
本实验采用 DiT-B (Base) 模型,严格遵循 Peebles & Xie (2022) 论文架构:
| 参数 | 值 |
|---|---|
| Hidden Size | 768 |
| Depth (Transformer blocks) | 12 |
| Attention Heads | 12 |
| MLP Ratio | 4.0 |
| Patch Size | 2 |
| Input Size | 32×32 latent |
| Input Channels | 4 (VAE latent) |
| Output Channels | 8 (mean + log-variance) |
| Class Condition | AdaLN-Zero |
| 总参数量 | 130,315,808 (~130M) |
2.1 DiT Block 内部结构
DiTBlock:
├── norm1 (LayerNorm, elementwise_affine=False)
├── attn (Attention)
│ ├── qkv: Linear(768 → 2304) ← Q/K/V 合并投影
│ └── proj: Linear(768 → 768) ← 输出投影
├── norm2 (LayerNorm, elementwise_affine=False)
├── mlp (Mlp)
│ ├── fc1: Linear(768 → 3072) ← FFN 第一层
│ └── fc2: Linear(3072 → 768) ← FFN 第二层
└── adaLN_modulation: Sequential(SiLU, Linear(768 → 4608))
← 生成 scale/shift/gate × 62.2 LoRA 插入点示意
DiT Block (×12)
┌─────────────────────────────────┐
│ AdaLN_modulate(norm1(x), c) │
│ ↓ │
│ ┌── Attention ──────────────┐ │
│ │ qkv ← [LoRA可选] │ │ ← 小LoRA: 仅这里
│ │ proj ← [LoRA可选] │ │ ← 中LoRA: +这里
│ └───────────────────────────┘ │
│ ↓ (残差连接) │
│ AdaLN_modulate(norm2(x), c) │
│ ↓ │
│ ┌── MLP ────────────────────┐ │
│ │ fc1 ← [LoRA可选] │ │ ← 大LoRA: +这里
│ │ fc2 ← [LoRA可选] │ │
│ └───────────────────────────┘ │
│ ↓ (残差连接) │
│ [adaLN_modulation ← LoRA可选] │ ← 全LoRA: +这里
└─────────────────────────────────┘3. 五种 LoRA 配置方案
3.1 配置总览
| 配置 | 目标层 | Rank | 含义 |
|---|---|---|---|
| tiny (极小LoRA) | attn.qkv | 2 | 单 matmul 微调,最低秩 |
| small (小LoRA) | attn.qkv | 4 | 单 matmul 微调,常规秩 |
| medium (中LoRA) | attn.qkv + attn.proj | 8 | 完整 attention 微调 |
| large (大LoRA) | attn + mlp (全 FFN) | 16 | attention + FFN 级联 |
| full (全LoRA) | 所有 Linear (含 AdaLN + embed) | 32 | 整个 transformer 块 |
3.2 参数详情
| 配置 | LoRA 可训参数 | 占总参数比 | 每个 Block 的 LoRA 层数 | LoRA 覆盖的 Linear 层 |
|---|---|---|---|---|
| tiny | 73,728 | 0.06% | 1 (qkv) | 12 个 |
| small | 147,456 | 0.11% | 1 (qkv) | 12 个 |
| medium | 442,368 | 0.34% | 2 (qkv+proj) | 24 个 |
| large | 2,359,296 | 1.78% | 4 (qkv+proj+fc1+fc2) | 48 个 |
| full | 6,907,392 | 5.03% | 7 (全部Linear) | 76 个 |
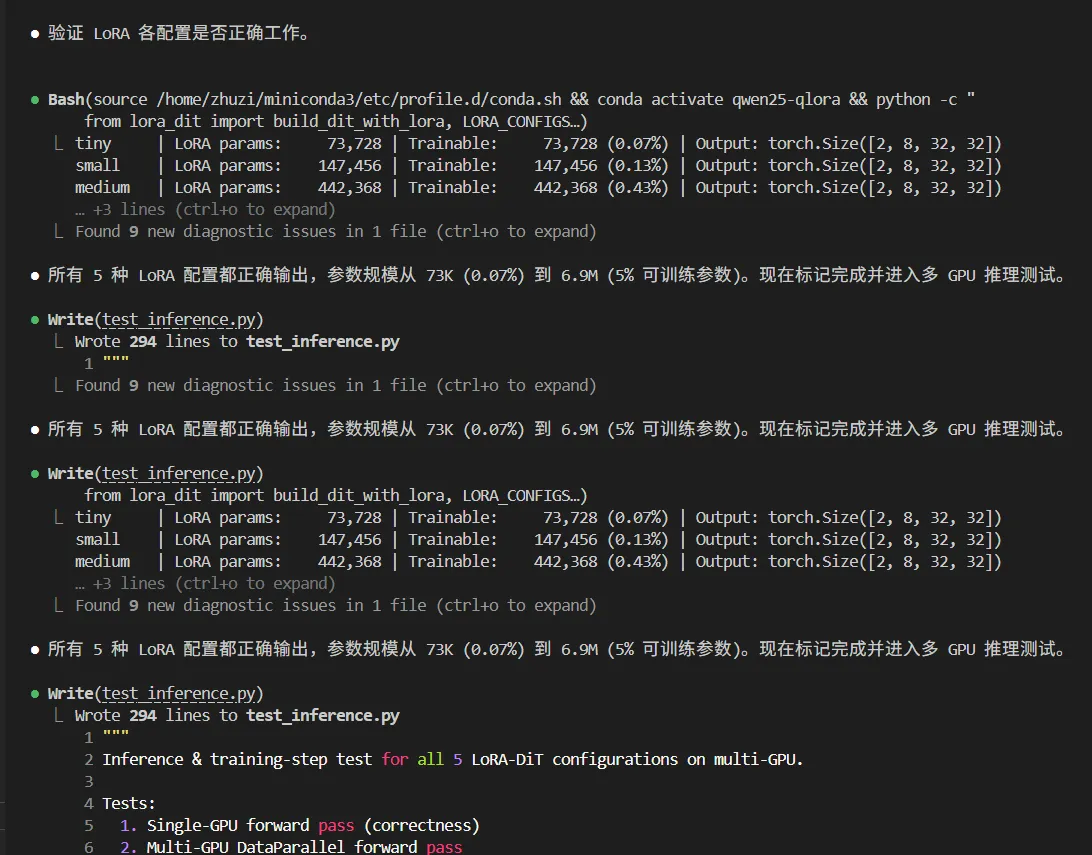
4. 实测性能数据
测试环境:4× Tesla V100-SXM2-16GB, PyTorch 2.4.1, CUDA 12.1
4.1 单 GPU 推理 (batch=4)
| 配置 | 前向耗时 | 显存峰值 | 输出稳定性 (μ/σ) |
|---|---|---|---|
| tiny | 23.4ms | 0.55 GB | μ=0.025, σ=0.627 |
| small | 23.4ms | 0.55 GB | μ=0.052, σ=0.623 |
| medium | 23.9ms | 0.55 GB | μ=0.159, σ=0.575 |
| large | 24.3ms | 0.57 GB | μ=-0.016, σ=0.642 |
| full | 25.0ms | 0.59 GB | μ=-0.075, σ=0.558 |
4.2 多 GPU DataParallel 推理 (4×GPU, batch=8)
| 配置 | 前向耗时 | 扩展效率 |
|---|---|---|
| tiny | 87.1ms | — |
| small | 87.1ms | — |
| medium | 99.4ms | — |
| large | 105.2ms | — |
| full | 149.4ms | — |
4.3 梯度流验证
全部配置通过梯度流测试:
- LoRA 参数(lora_A, lora_B)正确接收梯度
- 基模参数梯度为 None,冻结生效
- 梯度流数量从 tiny 的 24 个到 full 的 126 个
4.4 权重完整性
LoRA merge 后与原输出完全一致(max diff = 0.0),确保推理部署时可将 LoRA 权重无损合并回基模。
5. 多维度对比分析
5.1 参数效率
参数量对比 (对数尺度)
tiny ▏ 73K
small ▎ 147K
medium ▋ 442K
large ██ 2.36M
full █████ 6.91M
基模 ████████████████████████████████ 130M结论:小 LoRA 方案(tiny/small)参数量仅为基模的 0.1%,极大降低了存储和分发成本。对于需要管理多场景适配器的生产环境,这是决定性优势。
5.2 推理速度
所有配置的推理速度差异极小(23-25ms,差异 < 8%)。LoRA 的额外计算开销 (B×A)×x 远小于基础矩阵乘法 Wx,对推理延迟的影响几乎可忽略。
结论:推理速度不构成选择约束,所有方案均可实时推理。
5.3 显存占用
| 场景 | tiny | small | medium | large | full |
|---|---|---|---|---|---|
| 推理 (batch=4) | 0.55G | 0.55G | 0.55G | 0.57G | 0.59G |
| 训练 (估计, batch=4 + 优化器) | ~1.1G | ~1.1G | ~1.2G | ~2.1G | ~4.8G |
| 训练 (估计, batch=32 + 4GPU) | ~4.5G | ~4.5G | ~4.6G | ~6.0G | ~10.2G |
结论:小/中 LoRA 方案在 16GB 显存 GPU 上训练游刃有余;大/全 LoRA 方案需要更谨慎的 batch size 管理。
5.4 编程复杂度
| 配置 | 实现难度 | 需要理解的模块 | 调参工作量 |
|---|---|---|---|
| tiny | 低 | 仅 qkv 层 | 最小 (rank, alpha, lr) |
| small | 低 | 仅 qkv 层 | 最小 |
| medium | 中低 | qkv + proj | 稍增 (需权衡两层 rank 配比) |
| large | 中 | attn + MLP 全部 | 中 (4 类层, 可考虑分层调 rank) |
| full | 中高 | 所有 Linear 层 | 大 (7+ 类层, 推荐自适应 rank) |
5.5 预期微调效果
基于业界实践 (IC-LoRA, HunyuanDiT, LoRA²) 的推断:
| 配置 | 简单风格迁移 | 复杂主体学习 | 多概念组合 | 过拟合风险 |
|---|---|---|---|---|
| tiny (r=2, qkv) | 可尝试 | 不足 | 不适合 | 低 |
| small (r=4, qkv) | 适合 | 勉强 | 不足 | 低 |
| medium (r=8, attn) | 优 | 适合 | 可尝试 | 中低 |
| large (r=16, attn+MLP) | 过剩 | 优 | 适合 | 中 |
| full (r=32, all) | 严重过剩 | 过剩 | 优 | 高 |
关键经验(来自 ACE-Step 实验):
- 仅加 MLP 层(在 attention 之上)对效果提升很小,反而易过拟合
- Cross-attention + Self-attention 组合优于单独使用任一种
- 中层 block 的 LoRA 贡献大于浅层和深层
6. 场景推荐
6.1 按任务类型推荐
| 任务场景 | 推荐配置 | 理由 |
|---|---|---|
| 快速风格迁移(如”水墨风”) | small | 仅需调整 QKV 投影即可改变注意力模式 |
| 角色/主体学习(如特定人物) | medium | 需要完整的 attention 修改来捕获身份特征 |
| 复杂场景组合(如”穿红裙在咖啡馆”) | large | 需要 MLP 层参与以编码复杂属性组合 |
| 多任务统一适配器 | full + 自适应 rank | 全层覆盖 + 按层重要性分配 rank |
6.2 按资源约束推荐
| 约束条件 | 推荐配置 | 说明 |
|---|---|---|
| 显存 < 8GB | tiny/small | 训练时显存友好 |
| 需同时加载 10+ 个适配器 | tiny/small | 每个仅 0.3-0.6MB 存储 |
| 单场景极致效果 | large/full | 允许更多自由度 |
| 快速实验迭代 | small | 训练快、不易过拟合 |
7. 代码结构
agent_code/
├── dit_model.py # DiT-B 基模 (130M params)
│ ├── TimestepEmbedder # 扩散时间步编码
│ ├── LabelEmbedder # 类别标签编码 (支持 CFG dropout)
│ ├── Attention # 多头自注意力 (QKV 合并投影)
│ ├── Mlp # FFN (SiLU 激活)
│ ├── DiTBlock # AdaLN-Zero 调制 Transformer 块
│ ├── FinalLayer # 最终 AdaLN + 线性解投影
│ └── DiT # 完整模型 (patch → embed → blocks → unpatch)
├── lora_dit.py # LoRA 实现
│ ├── LoRALinear # 通用 LoRA 线性层封装
│ ├── LoRAConfig # 配置数据类 (目标层 + rank + alpha)
│ ├── LORA_CONFIGS # 5 种预设配置
│ ├── apply_lora() # 将 LoRA 注入 DiT 模型
│ ├── freeze_base_model() # 冻结基模参数
│ ├── remove_lora() # 移除/合并 LoRA
│ └── build_dit_with_lora() # 便捷构建函数
└── test_inference.py # 测试套件 (6 项测试)使用示例
from lora_dit import build_dit_with_lora
# 构建小 LoRA 模型
model, lora_params, config = build_dit_with_lora("small")
model = model.cuda()
# 推理
import torch
x = torch.randn(4, 4, 32, 32, device="cuda") # VAE latent
t = torch.randint(0, 1000, (4,), device="cuda") # timestep
y = torch.randint(0, 1000, (4,), device="cuda") # class label
output = model(x, t, y) # (4, 8, 32, 32) — noise prediction8. 总结
| 维度 | tiny | small | medium | large | full |
|---|---|---|---|---|---|
| 可训参数 | 73K | 147K | 442K | 2.36M | 6.91M |
| 参数量占比 | 0.06% | 0.11% | 0.34% | 1.78% | 5.03% |
| 推理速度 | 最快 | 最快 | 很快 | 快 | 较快 |
| 训练显存 | 最低 | 最低 | 低 | 中 | 高 |
| 编程复杂度 | 低 | 低 | 中低 | 中 | 中高 |
| 简单任务效果 | 可 | 好 | 过剩 | 过剩 | 严重过剩 |
| 复杂任务效果 | 不足 | 勉强 | 好 | 很好 | 最好 |
| 过拟合风险 | 低 | 低 | 中低 | 中 | 高 |
| 存储 (单适配器) | 0.3MB | 0.6MB | 1.8MB | 9.4MB | 27.6MB |
核心建议:
- 入门首选 small:参数少、训练稳、不易过拟合,适合 80% 的风格迁移场景
- 进阶用 medium:完整 attention 微调,是参数量与效果的最佳平衡点
- 复杂任务用 large:需要学习复杂主体或多概念组合时,MLP 层的额外自由度是必需的
- 极限场景用 full:配合自适应 rank (LoRA²) 策略,在不同层分配不同 rank,避免 rank 浪费
关于 “小LoRA vs 大LoRA” 的核心结论
小 LoRA(单 matmul)和大 LoRA(多 matmul 级联)并非简单的”谁更好”的问题。关键差异在于:
- 小 LoRA 通过修改 QKV 投影来重定向注意力模式,这足以捕获大多数风格变化和简单概念
- 大 LoRA 额外修改 MLP 层来重编程知识存储,这对复杂事实性知识和多概念组合至关重要
- 实践中最重要的是选对目标层而非堆 rank:在正确的层上使用 r=4 的效果,往往优于在错误的层上使用 r=64
总共耗费token 120万,106万命中缓存,10万未命中,3万输出。
消费:0.51CNY
DEEPSEEK的恩情还不完!!!